Motivation - Why BangDB?
The first question is why did we create a database from scratch? Writing database is very hard and it takes many years to have some basic stuff ready. Databases are one of the hardest software products to create, it involves and uses almost all parts of core computer science concepts, and one needs to solve numerous problems for every part of the system. So, it's obvious to ask the question. To have a proper answer, we would need to look at the current trend and observe it closely.
The Trend
There is a subtle but rapid change is going on for several years now, when it comes to "how data is generated and how it's consumed". Around 7-10 years ago or so, almost 95% or more data used to come from traditional sources, mostly created by humans. These data used to move with defined and predictable relatively slow speed. Majority of the data were text data and largely structured. Use cases required the actions resulting from the data in the form of reports, dashboards or something which were not hyper real-time in nature.

For the past 5 years or so, we see huge jump in the newer kinds of data coming from non-traditional sources. Machine is creating way more data than humans can create. All sorts of devices, log files, machines etc. are now streaming data from different disparate sources. These data have less defined structure and they come in all sorts of sizes and shapes yet, they are connected in some sense. These are real-time data where value is perishable if not extracted and analyzed in real-time too. The context is important, and we need to link different data to get the right insight. Need to act in real-time was never more emphasized than today. All of these are changing the users' and clients' requirements and even for a traditional humble use case, we need to address these things in proper way to solve the problem in satisfactorily manner.
While the trend is disruptive and happening with unprecedented speed and putting lots of pressure on the organizations, users, and developers to meet the requirements for their use cases, on the other hand, majority of the databases and systems in the market were created decades ago. This is creating an ever-increasing impedance mismatch which cannot be addressed using the older or existing traditional approach.
Use Cases
IOT analysis - Edge | devices| servers | sensors | CEP | monitoring
Text + video + audio - Hybrid data ingestion, store, find and analyze
Realtime streaming data analysis - forecast | predict | anomaly | continuous
Consumer Internet - personalization | lead score | conversions | recommendation
Fintech - local and distributed fraud analysis, real-time monitoring, recommendations
Vehicle sensor - device data analysis for predictive & personalized service
Root cause - Semantic, linked, graph, network data
Auto ML/AI - learning and processing streaming data | auto train, deploy, manage
Characteristics of the emerging data
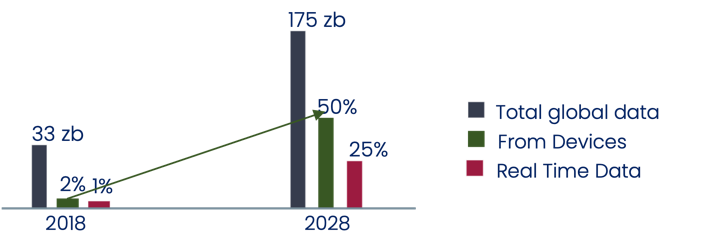
It's largely unstructured data. This is reflected in the growth rate of database which deals with unstructured data.
- 80-90% of data is unstructured, in all possible shapes, sizes and textures
- Data is moving with high speed, from all possible directions.
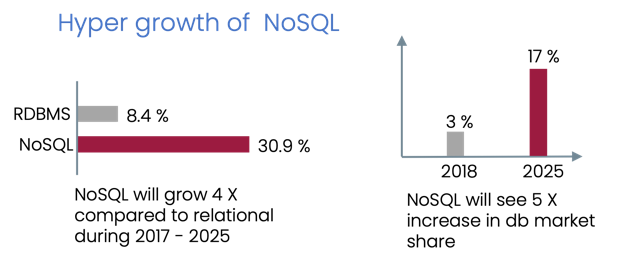
It's largely real-time data. This is reflected in the growth of real-time systems and databases.
- Data is largely time-series, value of data is ephemeral.
- Real-time and continuous access to intelligence is imperative.
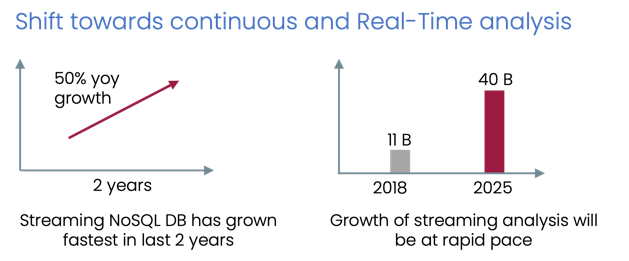
It's largely connected data. This is reflected in the tremendous growth of Graph databases in past few years.
- Data is interconnected, networked, interlinked, related, interdependent.
- Graph is required for better intelligence - property and semantic.
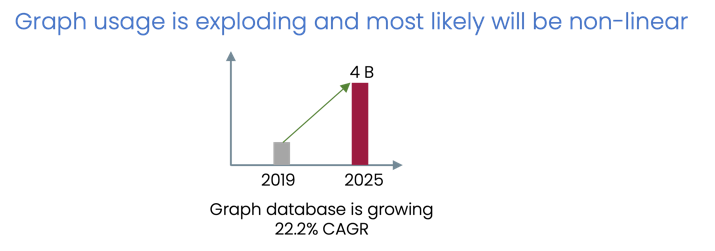
It's largely predictive data.
- Data is interconnected, networked, interlinked, related, interdependent.
- Graph is required for better intelligence - property and semantic.
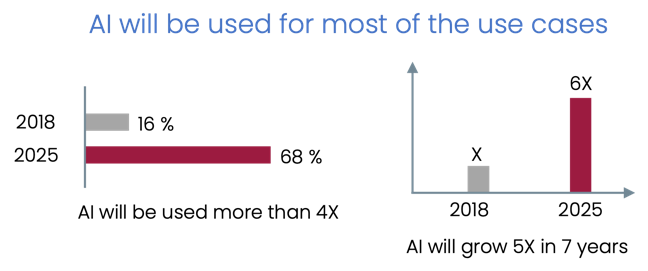
What's driving the trend?
Huge bandwidth, lower latency, and high penetration. | 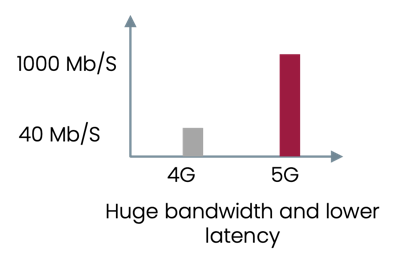 |
SSD is getting cheaper and faster and reliable. | 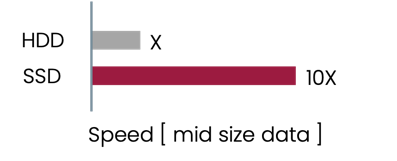 |
IOT sensors cost is decreasing fast - 50% in 5 years average. | 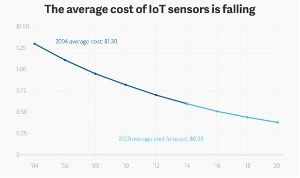 |
What's the major change?
Modern apps require fusion of different systems to process the data even for the traditional use cases. Which means we need to bring is all kinds of tools and tech, stitch them and then solve our problem in some way.

While document database allows us to process unstructured data, but other elements are needed to be brought in as well.
What's the major challenge?
Due to the need to handle many kinds of data at once to enable use cases, the developers and organizations are feeling compelled to bring in multiple different databases to create a required system.
- To complex and hard.
- Extreme resource intensive, huge cost and never-ending effort.
- Managing and scaling is too complex, takes lots of time.
- System security cross the boundary and developers need to handle part of this.
- Heavy and brittle application, shipping time keeps going up to a frustrating level.
As shown in previous sections, we have different tools and systems in different area, but the onus of bringing them together and creating a platform by stitching them together is on the developer or the organizations.
Stitching is such disparate and heterogenous systems is extremely hard which takes tons of high-tech resources and elongated period which results in huge spend upfront. Frankly, this can't be done by every company or team as this is totally different beast and needed to be done 100 percent in correct manner, else it won't work.
Even if we somehow create such system, we still need to create our solutions on top of it, which may keep demanding more features and support as we move forward. Further, scaling, distributing, deploying in hybrid mode and several other dev-ops items would also need to be considered.
Security of such system in enterprise environment is another big effort as we will need to somehow manage security homogeneity across these heterogenous systems.
Finally, it will be up to the application to provide the join, linking and correlation for data sitting in different systems which makes the application so rigid that it becomes almost impossible for organization and team to add new features in time for their clients and customers. Therefore, creating such system is not a prudent idea and hence this creates an opportunity as well for us to come in and fill the space.
Let's look at this bit more in detail and understand the issues that we can get into if we go with the approach of stitching existing different systems to implement the use cases.
- Takes too long to stich such a platform.
- Managing such system is nightmare.
- Higher latency, lower performance.
- Higher cost, less automation.
- Each silo vertical is different scale unit, quite disparate in usage.
- Poor resource utilization tends to have uneven patches.
- Adding a server is hard, costly, time consuming.
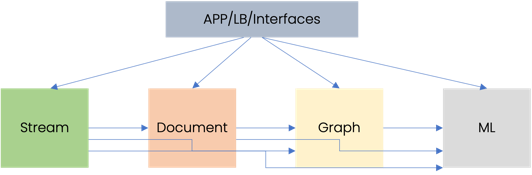
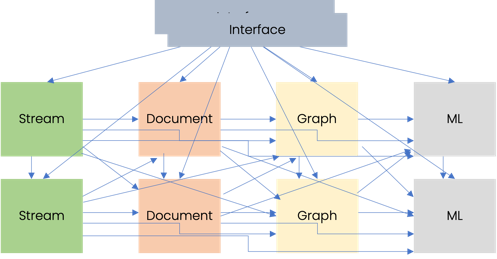
Options in the market
There are different systems / databases available in the market and there are many leaders in their respective areas as well. For example, Neo4j is leader in the Graph database space, but it can' handle document or time-series data well. Similarly, Mongodb is leader in the document database area, but it's very hard to bend it and align with the needs for streaming data analysis and deal with graph structure in truly native manner. Basically, we can't just take different databases and put them together to work like a single combined system. And we also can't force all data to align with one database structure and pretend to solve the problem which in the first place needed to keep the data structure and context intact.
Many of these databases also lack some of the core database support required for dealing with scale and performance. Such as overflow to disk with performance within the reasonable bound. True concurrency to leverage the machine resources well for high performance required for some of the use cases in real-time.
Why document database alone is not sufficient?
We can argue, why a Document database is not sufficient to handle all types of data? Using the same logic, why a Graph database is not enough to deal with different kinds of data? Let's try and see why they alone are not adequate and, it's not recommended to force fit.
- Document database is not a stream processing engine. Which means if we can in true sense stream time-series data and expect to do event processing and action taking in real time.
- Need Stream for Real-time ingestion and analytics
- Continuous data processing and query
- Need to find patterns & anomalies on streaming data
- Need to compute Running aggregates and statistics
- Need to Train models, predict on streaming data
- State based continuous CEP and actions in real-time
- Map-update instead of Map-reduce
Just having timestamp as primary key wouldn't be enough to treat document database as stream processing database.
- Document database is not a Graph processing engine. This seems bit more obvious as how do we force a triple (subject, object, and predicate) to be stored withing document store with structure preserved for efficient queries and future tasks. Further, graph database can use AI well in largely implicit manner due to its natural layout, if properly preserved.
- Graph native integration with the stream processing.
- Storing nodes and triples (subject, object, and predicate)
- Graph native algo support requires different store model.
- Leveraging the relations for queries over the network
- Storing nodes and triples (subject, object, and predicate)
- Ontology and property graph requires traversing links.
- Avoiding run-time relation-based joins
Just having "refid" embedded in the document, is not enough to treat document database as Graph processing database.
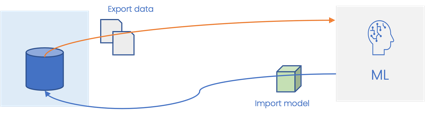
- Document database doesn't have AI right where data is. Which means we need to export data to a AI layer, deal with ML ops, train model and then import the model back into the system or use it at application level. This is clearly not scalable model. Also, it makes several jobs inefficient or time taking, error prone for constant and continual update of ML models.
- It remains largely manual task to train models [ even when metadata is largely fixed ]
- Versioning, deployment of models remains a challenge.
- AutoML - very hard from infra perspective
- Metadata, data, models all mostly, are not sync