Access Methods
BangDB implements two types of data structure methodology to implement indexes for keys in order to retrieve the data quickly, and they are:
- Btree
- Ext Hash
All these types are available as configurable parameters and user can select as appropriate for the table. Note that once a particular method has been selected for a table then for its entire life index method can't be changed.
Btree (B+Link*Tree) data structure methodology
BangDB actually implements varient of Btree, namely B-link-Tree tree based mostly on Lehman and Yao's “Efficient Locking for Concurrent Operations on BTrees”.The BangDB's implementation has worked on the concept defined in the paper and has taken it further to enhance the performance by increasing the concurrency significantly. BangDB also does selective caching of few highly accessed pages and related information to improve the performance.
The main highlight of Btree for BangDB are:
- Minimal locking for various operations, compared to other dbs which typically tends to lock major or full portion of tree
- Search and get does no locking
- Insert or put locks two - three pages, which is less than 0.004% of the overall pages in the db (if taking 50,000 pages for 5-7 million keys)
- Multiple threads can work on the same Btree data structure concurrently to get or put keys, which allows the db to leverage multi cores machine very efficiently
- It's a deadlock proof design and implementation
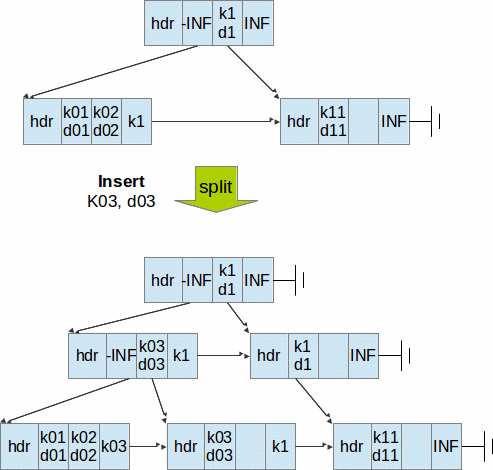
When to use Btree?
Btree should be used for storing data when order is important. For example, to be able to retrieve data using range scan or query, it's very important that keys are sorted and stored in the order such that the range based selection can be done.
Hash (ExtHash*) data structure methodology
BangDB implements the variation of hash, namely extending hashing based mostly on Hsu and Yang's “Concurrent Operations in Extendible Hashing”. The BangDB's implementation has worked on the concept defined in the paper and has taken it further to enhance the performance by increasing the concurrency. BangDB also does selective caching of few highly accessed pages and related information to improve the performance.
The main highlight of ExtHash for BangDB are:
- Algorithm defines the ways for concurrent operations on hash files.
- Search and selection of a particular page is based on verification rather than locking pages.
- Insert or put locks two pages most of the time which is again less than 0.004% of the overal pages in the db (if taking 50,000 pages for ~7 million keys).
- Multiple threads can work on the same Hash data structure concurrently to get or put keys, which allows the db to leverage multi cores machine very efficiently.
- It's a deadlock proof design and implementation.
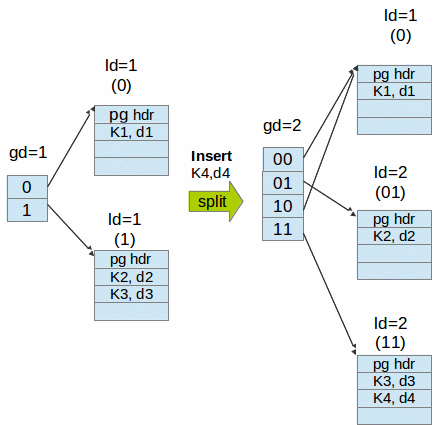
When to use Hash?
Hash should be used for storing data when order of the keys are not important. Note that the scan API can be used for hash based table as well but the range based scan is not possible. This means that user can use scan to select all the keys and values from the db and iterate over them but they can't provide any range for scan as it would be meaningless since hash doesn't maintain any order.