Multi flavour
BangDB is a multi flavor database that runs in different ways as required by different use cases. For example, if an app needs to run in device or microprocessor or server, but the app requirement is to link the db directly into the program or process then BangDB could be simply used like that. BangDB runs in Raspberry pi, or linux, windows or Mac as required. It's very similar to the way BerkeleyDB runs or LevelDB runs.
There are plenty of use cases where embedded and multi flavor database is needed. But in the case of IOT, there are many reasons why embedded BangDB would be useful. Hyper local analysis demands this way of functioning and it has numerous benefits.
For example, since the BangDB will be within microprocessor therefore it will be able to do some analysis, find some patterns and take some action immediately without having to wait for server for response after forwarding data to it.
By doing this we achieve the level of latency we need for users to take decision faster which could result in significant saving of time, cost and productivity. Further we reduce the amount of data to be sent over the wire to the cloud which could result in huge cost, energy saving. Therefore, embedded computing and analysis is the need of the hour.
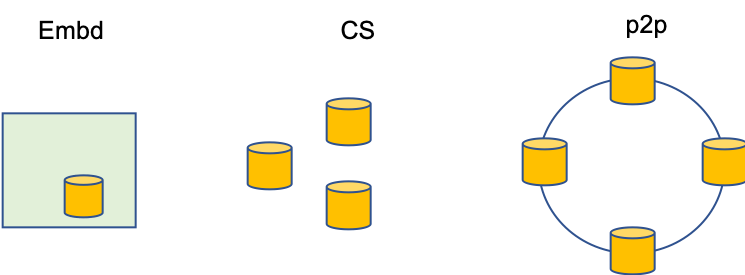
BangDB also comes in Client Server mode, where clients connect and interact with the server over the network. Server may have slaves attached to it where data could keep replicating to the them from the server. This model is pretty good for many use cases and also to handle larger amount of data and do lot more computations than it is possible in embedded scenario. Majority of the use cases would fit this model and from both volume of data, speed of processing and also use cases perspective.
BangDB also runs in fully distributed mode where the data is distributed among different participating nodes. This is achieved using consistent hashing over a virtual network overlay implementing chord algorithm. This is a masterless scenario implemented using p2p model, which allows high level of churning in the cluster. It's highly suitable for linear scaling for higher volume of data with minimal admin support required to maintain the system. This is also suitable for scale up and down at run time in a simple manner which may result to cost efficiency and at the same time high performance for huge amount of data.
Finally, BangDB enterprise comes with an interactive dashboard and portal behind it to allow developers and users to create applications (apps) in a real simple manner with little or no coding at all. This allows domain experts to build use cases and deploy in time accelerated manner in simple dashboard driven manner.
There is a AppStore associated with it and apps could be further published for someone else to simply download, configure and use it. We have built several apps and they are already published for users to simple take and use it for powerful use cases in the domain like ecommerce, payment, data center, infrastructure, etc.
Integrated AI and Stream allow users to simply ingest data, create models, test and deploy models with just few clicks. This gives lots of power and capability to the users who know what they want to build leaving heavy tech lifting to the BangDB.