Throughput-1B-Records
BangDB Throughput for 1B operations [ put and get ]
Throughput-1B-Records - Goal of this benchmark is to find out the throughput of db where we put data and then get them using multiple connections with all features of the db remain ON. The benchmark is run for BangDB server, however, similarly we can run for embedded as well and the data would be comparable.
Here are several charts, depicting the runs for BangDB Server.
1B Put
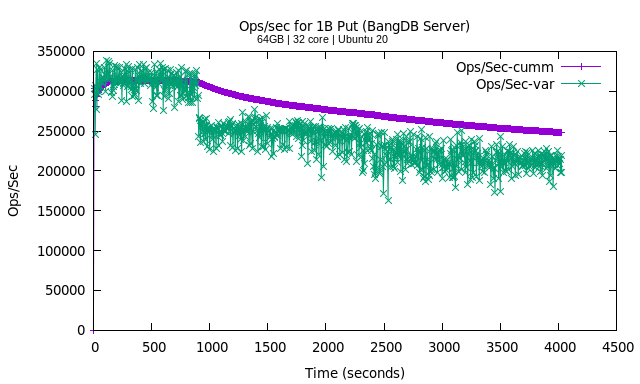
We notice that the average throughput of the server was around 250K ops/sec. It started with above 300K mark but soon it goes down to a stable 250K mark. This is because after filling buffer pool for some limit, db starts flushing the data to disk based on the set configuration. Note that the behavior can be changed by tweaking the configurations based on need. The DB at the same time was also flushing WAL logs and checkpointing as well. Unlike many other NoSQLs, BangDB keeps checking and flushing the data in continuous manner as much as possible.
1B Get
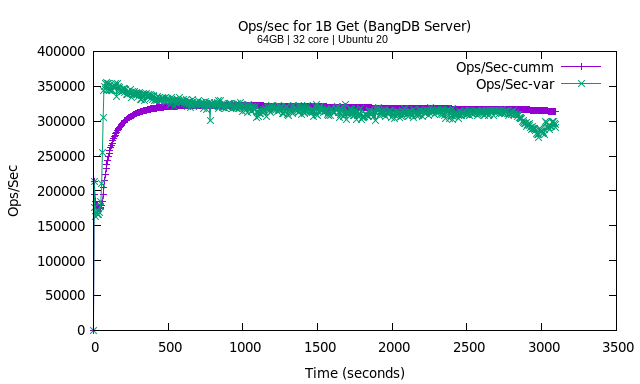
With get, we note that the variability for the ops/sec is much less than when compared to put and it makes sense as with put, we have lots of flushing/write activities also going on. With read too, db does some writing (checkpointing, unflushed logs, or simply log reclaim etc.). The avg throughput is close to 315K ops/sec for get
Put and Get comparison [ race to 100 percent ]
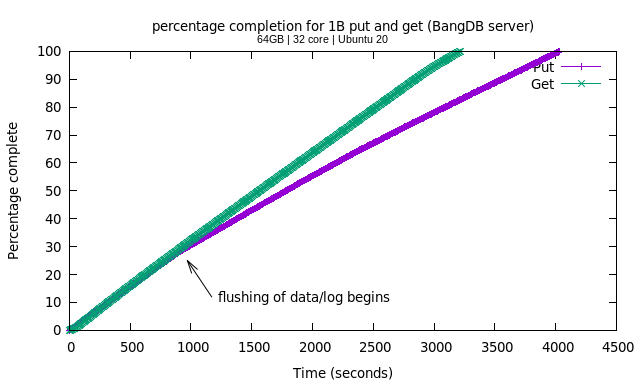
While get is almost a straight line, indicating consistent throughput for 1B records, put bends slowly due to increasing writes to the disk
How to run
This is simple benchmark and can be run easily on a commodity or other servers. Minimum requirement to run BangDB is 4GB RAM with 2CPU, however it will be good to get better machine to run throughput 1B benchmark. Also, user may run the benchmark with different number completely, for example, we can run it for 10M records with 32 connections/threads.
The entire code for the benchmark is available here. The same benchmark can be run for embedded db as well, the code for both server and embd is available at github.
Also note that, there is C++ test app and Java test app available, and you may run from either of these. The build script is there to help It's very simple to run the benchmark, simply take the BangDB, take the bench, follow the instruction given in the README and that's it. Below is the details for running benchmark for Server using java test app Here are the steps to run the bench First, let's build the bench
bash build.sh
If successful, now you may run tests
bash exapp.sh
Or, to put 1M key and val using 16 threads
bash exapp 16 1000000 put
Or, to get 1M key and val using 16 threads
bash exapp 16 1000000 get
Various options are:
usage: bangdb_bench kv/doc/stream num_threads; num_items put/get/scan/all/overlap [factor(optional define only with overlap)] factor 1; the factor defines how much read and write 1/factor part write and rest read. ex; factor = 3, 33 percent write and 67 percent read Running the default test with 16 threads (connections), put and get 1000000 items etc...