Core Database Design
BangDB 2.0 core design
BangDB core database is designed and implemented for following high level goals:
- DB should have full control on data
- DB implements its own buffer pool and cache
- DB implements its own buffer pool and cache
- DB implements its own buffer pool and cache
- Read, write both should be fully concurrent
- DB should have full control on IO and manage it well
- Data should be durable and recoverable in case of system crash
- DB should support transaction
- Key arrangement should be sorted and hashed
- DB should manage memory efficiently
- Performance of DB should be very high
- DB should run in devices to big servers
- DB should be persistent and in-memory
- DB should retain performance even when data overflows the working memory size
- DB should manage itself and do housekeeping as required without admin
Basic data handling
BangDB core implements its own buffer pool where it maintains the pages for index and data files. The buffer pool is basically a hash table with linked nodes. It also contains several other lists such as lru list, dirty page list, prefetch list etc..
There is another list, free list which maintains the free pages. The buffer pool can be private and created for each table or could be shared (default) whereas the free list is per database
Having own buffer pool, allows db to treat different pages in the db differently. This gives the db an edge over simply relying on OS pool as that would not apply the local contextual information for page flush or fetch algorithm. Whereas BangDB can leverage these data and apply them in having better suitable adaptive sequential page prefetch and flush algorithm
Few basic components of the overall page, IO, memory management components are discussed below.
Data durability and log
BangDB implements write ahead log. Basically all the changes to data and index files are written only after the log is written. The logging is available as part of one of the configuration parameters and user can set it on/off as required. But once set for a table, the log will remain in same position (on/off) for all its life.
Write Ahead Log (WAL) is always sequential and multiple sequential logs file are being generated in the life of the db. BangDB tweaks the basic design and algorithm for write ahead logging in order to reduce the amount of data to be logged and thereby improving performance without sacrificing on the core basis and benefits of the write ahead logging. It uses modified ARIES algorithm to implement the wal. The modification is basically to optimise the log-size/data-size ratio to improve the performance.
Following are the benefits of Write Ahead Log (WAL) :
- Reduces the number of seeks- since log is always sequential, hence improves IO and performance.
- Checkpointing- faster to recover in case of data recovery, can be switched on/off.
- Crash recovery- DB can recover from any crash and bring the database to a consistent state (state at the time of crash).
- Durability- Since logs are written before the actual commit of data or index file changes along with data recovery mechanism, the data durability is not dependent upon the write to data or index files.
- Transaction - Write Ahead Logging is the standard approach for transactional logging.
Write Ahead Log (WAL) can be used in following manner:
- Shared Log
- Private Log
The shared or private are w.r.t table. For example if shared log is used (default way) the all tables will share the log. It helps optimise the IO, however there are certain cases where separate log is required for table and in that case private log comes handy as it creates separate log file for the table. Table which is very often used or high in data volume etc.. are few cases where private log may make sense.
The BangDB implements write ahead log, the ARIES algorithm, for data durability and atomicity. The db always writes a log for every write operation even though it doesn't persist the actual data to the disk. Since db performs all its operations from the buffer pool and doesn't go to the disk at all if not needed that means all the data written in the buffer pool can vanish if the process is killed and data can be lost.
Writing log for all data modification operation ensures that the all operation log is maintained and frequent flushing of the log to disk ensures that the data can be recovered from the log if required. The write ahead log provides the data recovering capability when required. For example in the event of process or machine crash etc…, BangDB recovers the data when restarted and brings the db to the state where it was when it crashed.
The log is sequential and it's flushed to the disk by the background workers frequently. The user can set the frequency based on the need, higher frequency means data loss would be minimal in case of any eventuality. BangDB provides the flush frequency knob with impressive Milli sec (theoretically can be in micro sec) as the least count. The default frequency is 50ms and db performs very good even at this frequency.
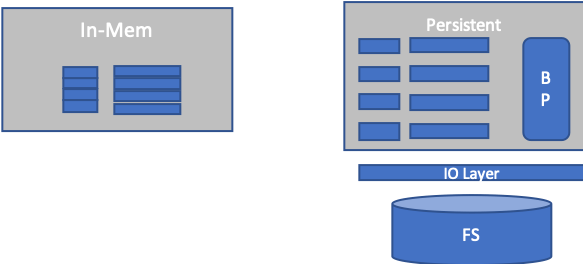
In-memory persistent
BangDB is designed to run in persistent or in-memory mode. By default it runs in persistent mode and log may be switched ON or OFF as per configuration. By default log is always ON. However, there are scenarios where in-memory could be best, For example: cache.
But in majority of the cases, persistent mode is best suitable. When db is run in in-memory mode then log is switched off, transaction can't be ON and it works within the allocated memory budget. Whereas when it runs in persistent mode with log ON, then it can go beyond working memory set and still remain performant. BangDB implements IO Layer and mechanism to reduce the disk IO especially random IO to maximise the throughput.
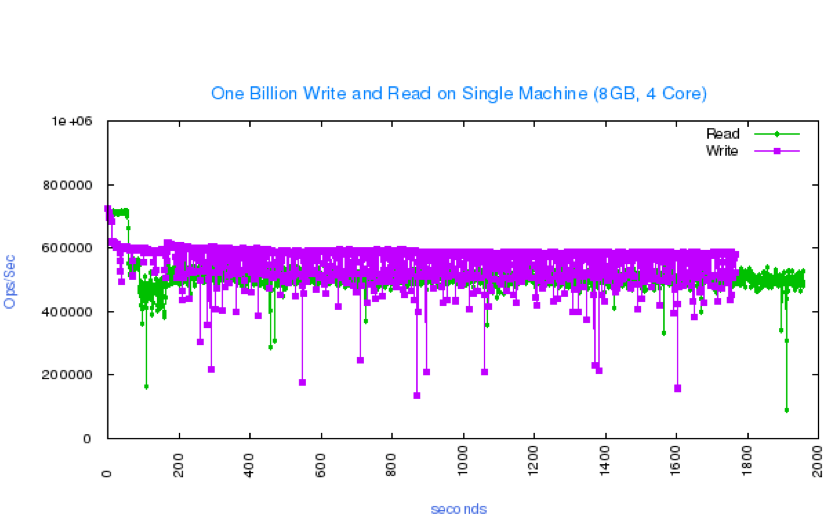
IOPS Performance
BangDB gives very high performance and it's designed for the same. Read and write both are fully concurrent and hence it leverages the available resources on the machine to fullest of its capacity. Also, it implements IO Layer which intelligently keeps track of several data structures and takes right decision or predict best next steps when it comes to minimising IO for higher performance.
Here is simple Billion IOPS data on a commodity hardware with less 4 core and 8GB RAM